Week Twenty-One: Refactoring and Integration Testing
This week we made a start on integration testing, and spent a large portion of time refactoring our code. Even though we refactored our code just 3 weeks ago, there still remained plenty of room for improvement. After this, we focused on creating the diagrams for our project report website in time for our presentations which would take place the following week.
New Features
A new feature we added was the ability to filter data on line graphs by date. We used the daterangepicker library to place an input box on the top-right corner of every line graph which allows the user to select two dates between which to show graph data.
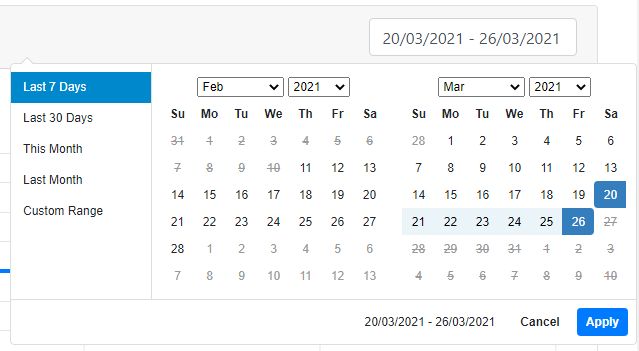
This date-range picker allows the user to select from a set of predefined ranges such as ‘Last 7 Days’ or ‘Last Month’, as well as allowing them to select a custom range using the calender widget. Certain dates are crossed out as there is no data show for these dates.
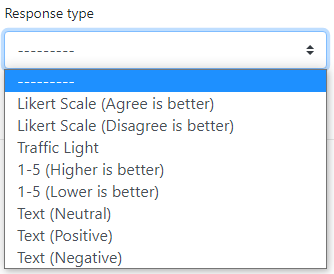
One problem we discovered with our program was the assumption that higher valued responses are better, and thus deserve a higher score. For example, if the statement “I found this task difficult” had a likert scale response, then the “Strongly Agree” option would not be positive, as implied by our scoring system.
To solve this, we decided to give the Surveyor the option to choose whether higher values are better, or worse.
Integration Testing
Although we had completed Unit Testing for our web application, this only tests individual components of our program independently. This means that bugs which occur due to the interaction between different components of the program may get missed by this type of testing. As such, we used Cypress to implement Integration Testing for our web application, which tests that the different modules of our program interact with each other in the way that we expect.
We chose to use Cypress due to its very extensive, clear documentation. In addition, the tests are written in node.js, which results in concise tests which are easy to understand. An example of a test which tests the ‘Groups’ button on the sidebar menu would be as follows.
it('redirect to /groups when you click on "Groups"', () => {
cy.get('#sidebarMenu').contains('Groups').click()
cy.location('pathname').should('eq', '/groups')
})
Refactoring
When we last performed a major refactoring of our code, we moved most of the backend logic from the views.py files to utils.py files within each of the Django application folders. However, both of these files still had fairly large functions, many of them consisting of multiple steps, thus making them difficult to understand.
For the utils.py files we found that many of the functions had repeated code. To fix this we added a number of private helper functions, prefixed by an underscore, which would handle these common set of instructions.
As for the views.py files, most of the complexity in the functions was a result of the separate logic for handling GET requests and POST requests. To resolve this, we created a handler.py file in both the surveyor and respondent files. This allowed us to move all of the logic for handling POST requests from the views.py files to the corresponding handler.py files.
Another part of our code which we cleaned up were the templates. To begin with, all of the templates contained the HTML for static page generation, along with the JavaScript code at the bottom to render dynamic elements on the page. To make the structure of the code clearer, we moved all of this JavaScript code into separate .js script files located in the static/js/ directory. Along with the logical separation of code, this had the side benefit of allowing us to reuse scripts in multiple templates.
As we were refactoring our code, we found that we were repeatedly testing whether a question had a certain response type. Currently these response types were simply represented as integers, which made it to difficult to understand the purpose of the code. Therefore, we produced the enum types below to represent each of the different response types.
class ResponseType(models.IntegerChoices):
LIKERT_ASC = 1, _('Likert Scale (Agree is better)')
LIKERT_DESC = 2, _('Likert Scale (Disagree is better)')
TRAFFIC_LIGHT = 3, _('Traffic Light')
NUMERICAL_ASC = 4, _('1-5 (Higher is better)')
NUMERICAL_DESC = 5, _('1-5 (Lower is better)')
TEXT_NEUTRAL = 6, _('Text (Neutral)')
TEXT_POSITIVE = 7, _('Text (Positive)')
TEXT_NEGATIVE = 8, _('Text (Negative)')
Since these enum values were used to represent a field in a Django model, we inherited from the django.db.models.IntegerChoice class instead of the standard enum.Enum class from Python’s 3rd party enum package.
In addition to this, we also added a number of helper functions to the models which could be accessed as properties. An example of this would be the function below to determine if a question has a text response type.
@property
def is_text(self):
return self.response_type in [
Question.ResponseType.TEXT_NEUTRAL,
Question.ResponseType.TEXT_POSITIVE,
Question.ResponseType.TEXT_NEGATIVE
]
Diagrams
In preparation for our presentations next week, we took some time out to produce class diagrams and sequence diagrams for our project.
We produced class diagrams to show the relationships between the Django models using the graph_models command from the django_extensions package.
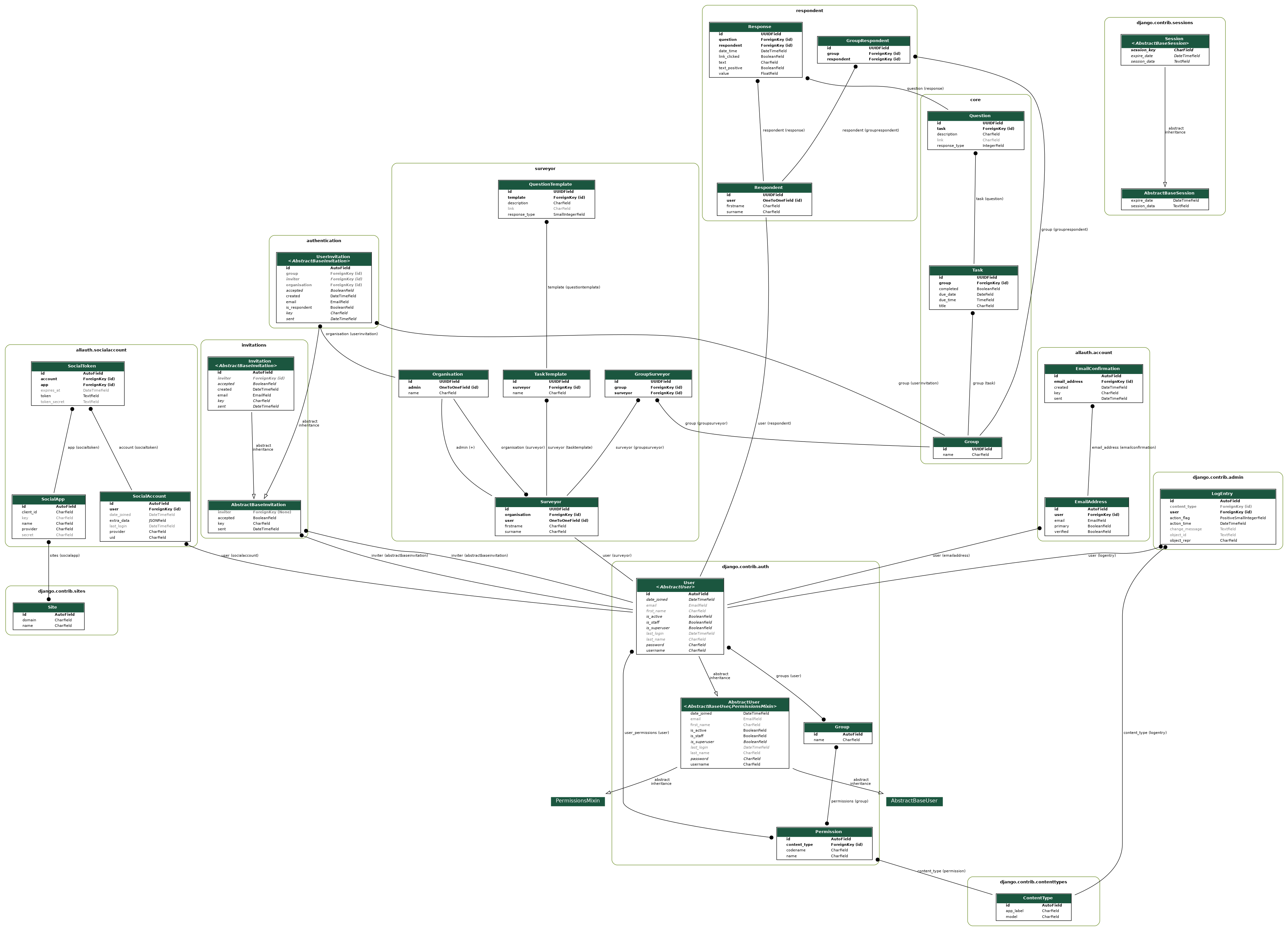
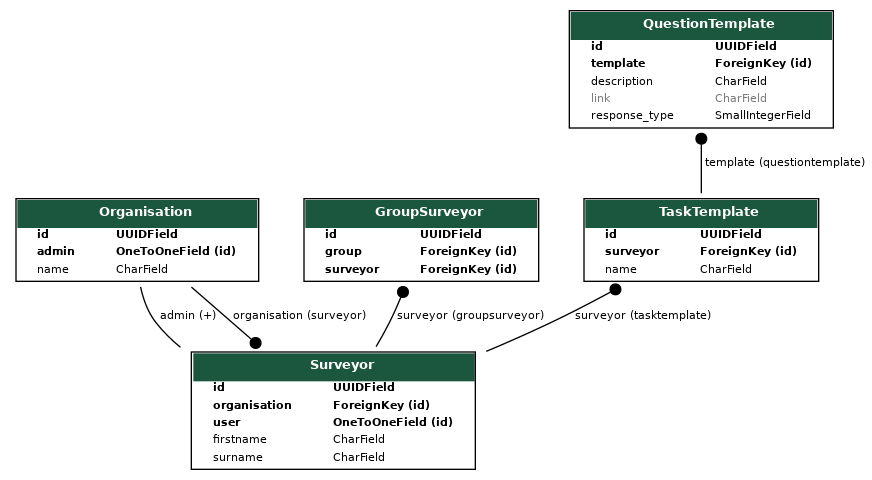
This class diagram shows all of the models in our project and how they relate to each other. Although it provides a good high level overview, it is difficult to see detailed information about any particular set of models. Therefore, we also produced separate class diagrams to show the models in each of the individual applications, such as the one shown below for the Surveyor application.
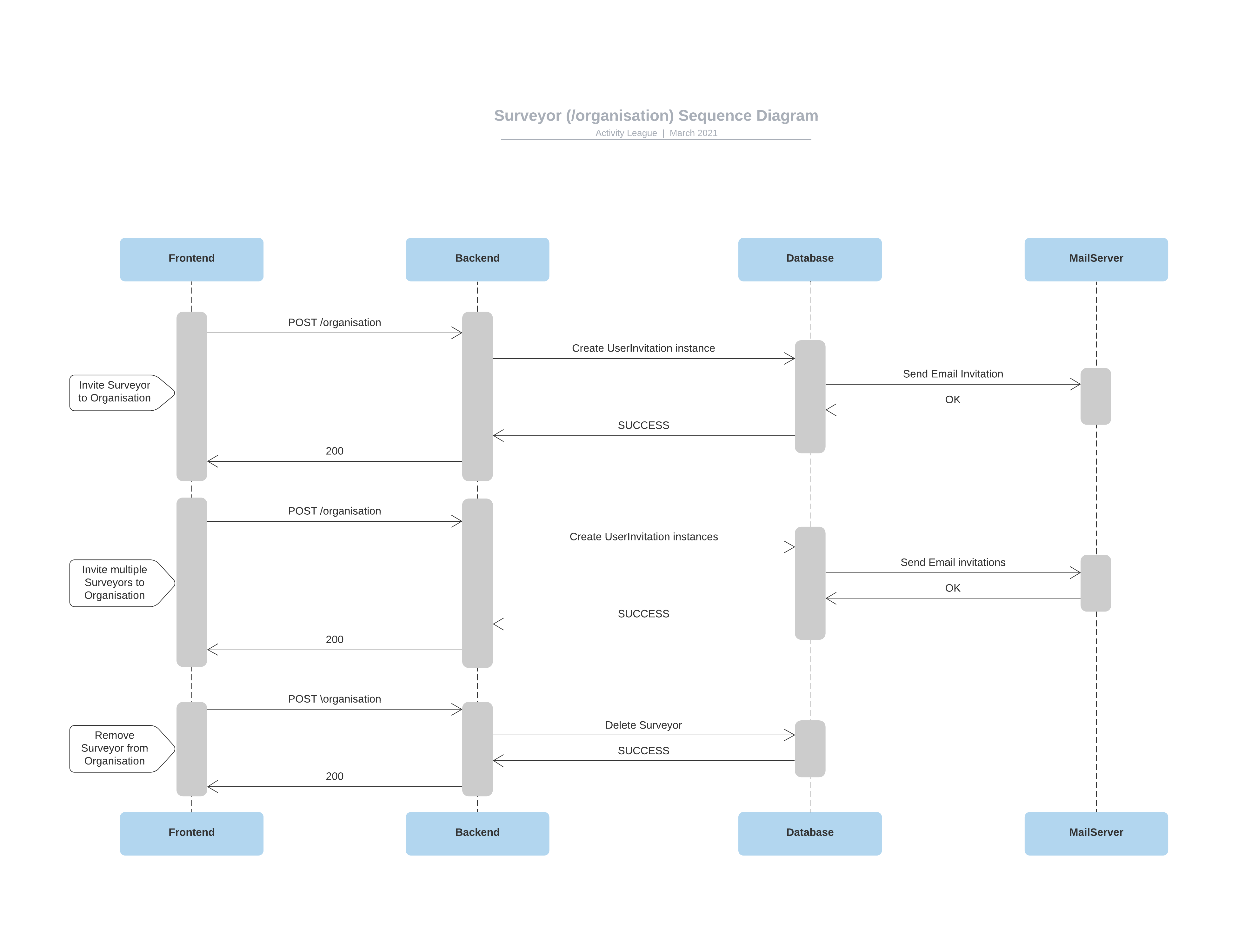
In addition to these class diagrams, we also produced sequence diagrams to show the different interactions on each page in time sequence. These sequence diagrams follow the same structure as the one shown below for the ‘Organisation’ page.
Next Steps
Since we have refactored a large portion of our codebase, as well as added new functionality, many of our tests will no longer be working. Next week we will work on fixing these broken tests, and adding new tests to cover recent additions to the code.
We will also begin to privatise any sensitive information stored in our configuration files, such as the login information for the database, and the Client IDs and Secret Keys for our SSO providers.