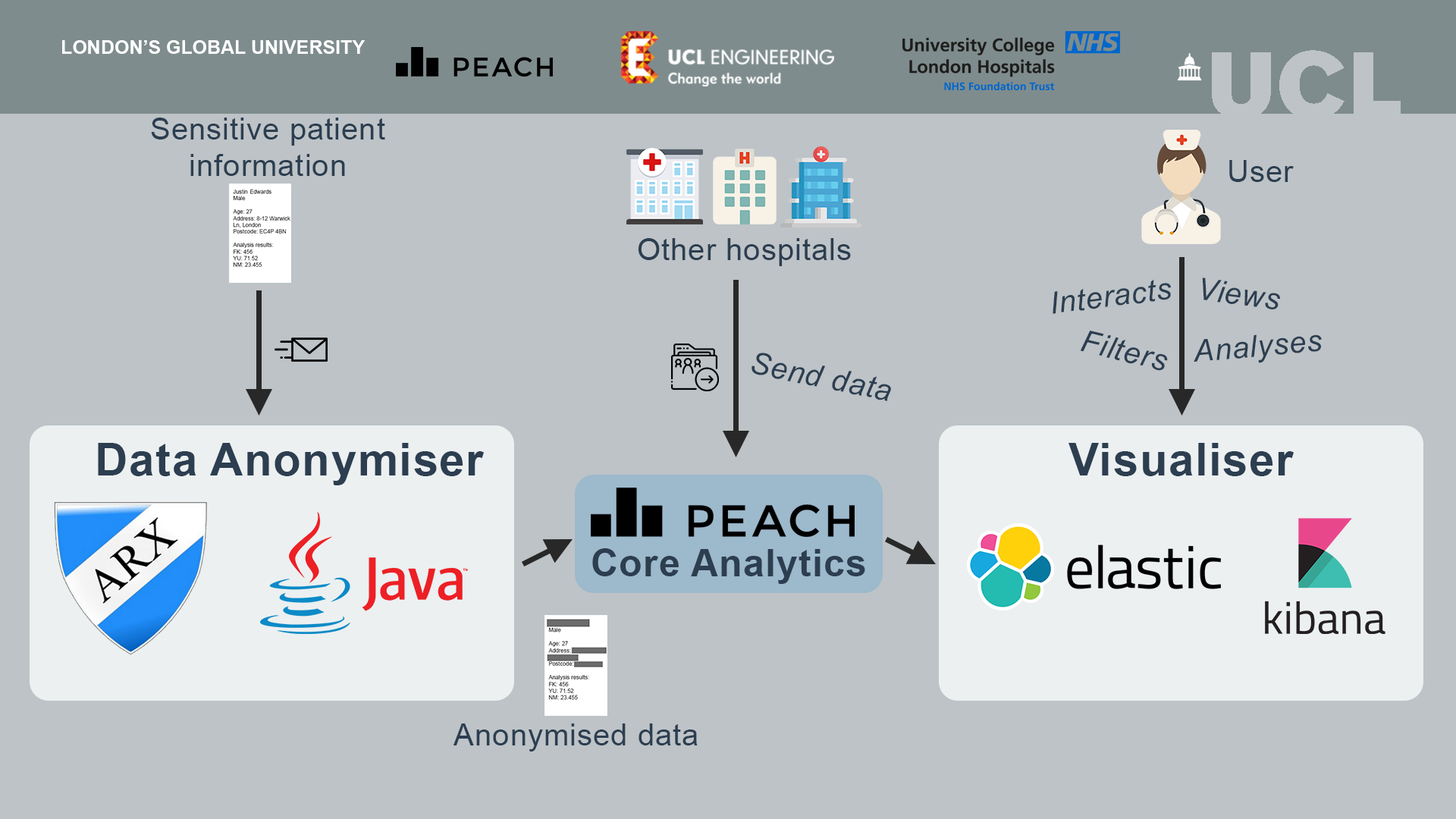
System Archiecture
Our system consists of 2 parts, a data anonymisation tool and analytics visualiser.
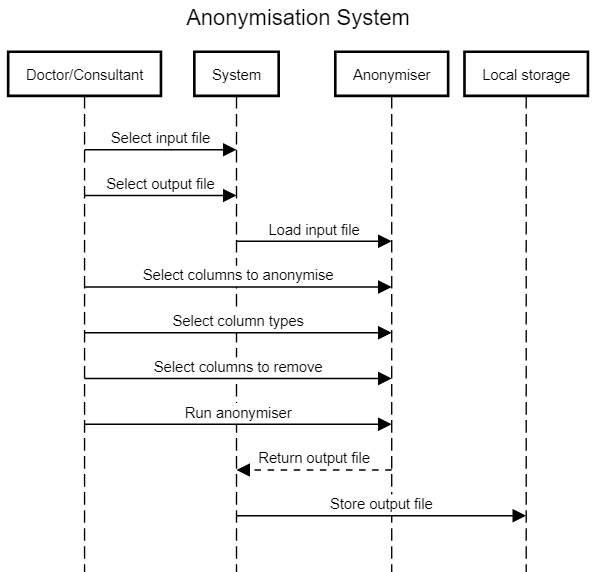
Data Anonymiser
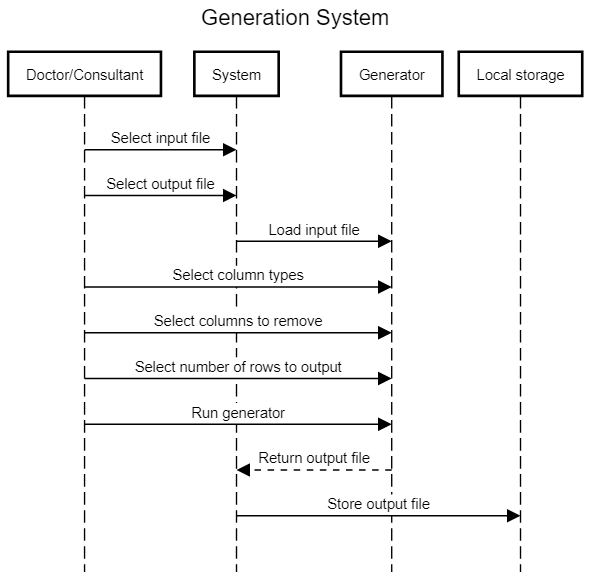
The data anonymisation tool is used by doctors to anonymise sensitive patient data for further research, data analytics processing and for statistical purposes. To do so a doctor selects an input file with sensitive patient information and chooses which parts of this data should be anonymised. Our solution produces a anonymised data file which can be sent to PEACH core analytics for further analysis. Programmed in Java, the anonymisation tool has a user interface written using Java FX and uses the ARX library for anonymisation.
Analytics Visualiser
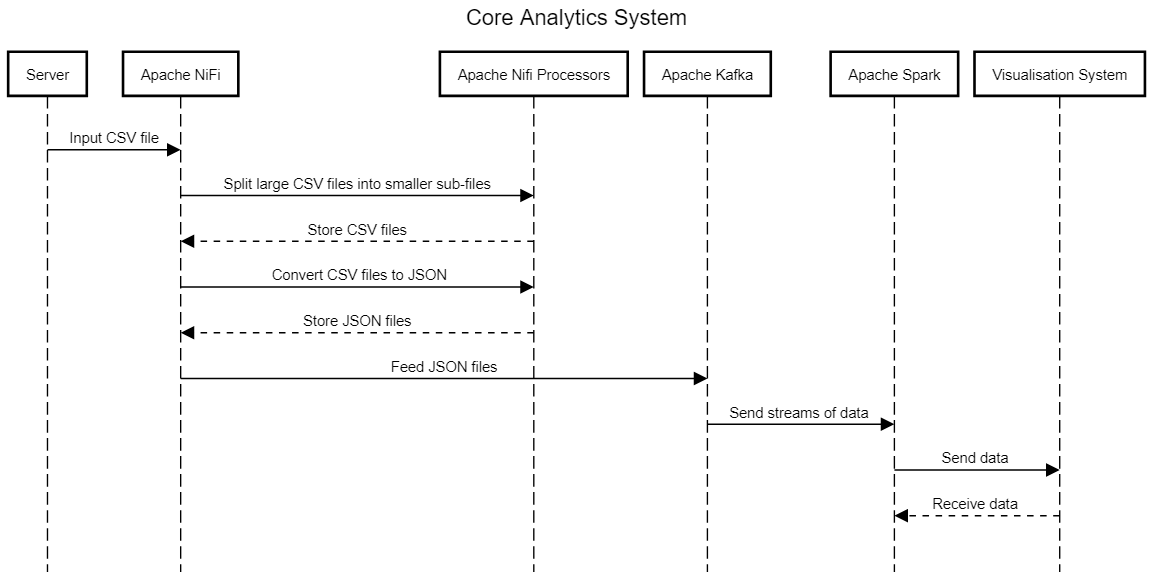
All the data which is processed by the PEACH core analytics system can be used in our visualiser. A data scientist can plot and customise graphs based on the input data. For example if a researcher wants to analyse the effectiveness of a new cancer treatment, these graphs could provide better insight into the results and potentially help to improve these medications. The visualiser is based on the Elastic stack and Kibana.