Summary of Achievements
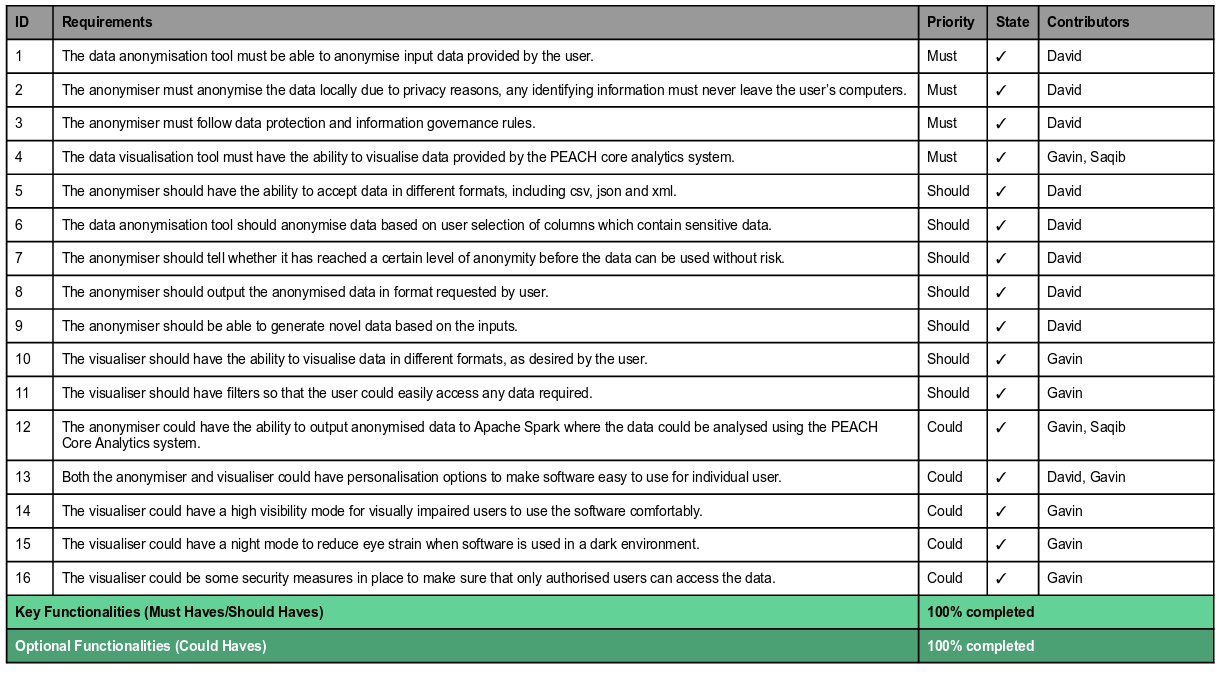
Achievement Table
Known Bugs

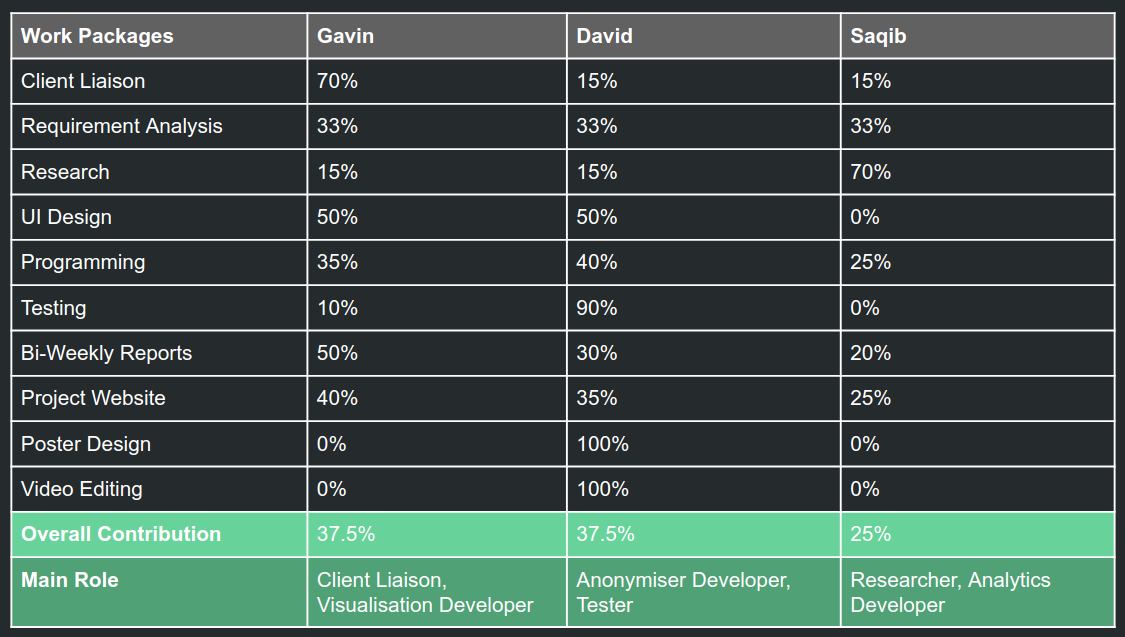
Individual Contribution Table
We managed to successfully create a tool that anonymised data inputted by the user in various formats. Our tool accepts data and anonymises it accordingly with the user’s configurations so that the data no longer contains sensitive information and could be sent through the Core Analytics System. The avoidance of transmitting sensitive data also ensure that data protection laws are followed. We also extended the Core Analytics System by adding an open-source visualiser tool which allows users to visualise the data in many different formats. This solution is particularly effective because any authorised user could access this system and the running costs will remain the same. We successfully met the requirements laid out to us by the client.

We feel that we provide a good user experience with both applications created in this project. The data anonymisation solution provides a simplistic design which allows users to easily navigate the various features of the application. Having taken user feedback throughout the design process, this desktop app is tailored for users. However, should we undertake this project again, from a user experience point of view, we would aim to provide a UI with a more contemporary feel by incorporating more modern elements within the interface.
The upload website provides a minimalistic interface which leads to the visualisation solution. This provides a simple tool which allows patient data to be visualised in interactive and graphical ways. However, it is not possible to search for insight in a natural language, as many of our users requested in the HCI part of our project. For instance, it’s not possible to ask “How effective is the new cancer treatment” and get graphs as a result. Thus, should we have more time to work on this project, we would be looking to incorporate features such as this to maximise user experience.
From a functionality point of view, this project has met all requirements set out at the start of the process and agreed upon by both the client and the team. As a result, we feel that this project has been very successful and we have endeavoured to produce quality solutions with clean code and good designs. However, should we are to undertake this project again, we would aim to implement more data pipelines within the analytics system so that data mining techniques could be applied on the anonymised data. This would then provide more useful data on the Elastic Stack so the project can be used more effectively. Nevertheless, even with a simple data pipeline, we are able to demonstrate this system’s key features and the need for an anonymisation tool and analytics platform in the healthcare industry.
Having deployed the system on Microsoft Azure, the system is stable, has been stress tested and is reliable. Should the number of requests be within reason, the analytics system is able to sustain high amounts of traffic and huge amounts of data transfer. It should not require steps to be taken regularly to ensure the system is stable.
Furthermore, since the many parts of the system have well defined APIs to communicate with each other, breaking changes in libraries can be easily solved by only having to redevelop parts that require necessary re-implementation. Currently, the system is deployed on an Ubuntu Server virtual machine but for scalability purposes, it may be wise to move to a distributed operating system such as DC/OS in the future.
Throughout the development of the anonymisation and visualisation applications, we have aimed for efficient solutions. The anonymisation tool employs the use of the ARX library to quickly and accurately process the data whilst the analytic system uses Elasticsearch as a solution for storage. The elasticsearch system allows data to be stored, indexed and easily searchable through queries. Since it is highly efficient, especially with huge amounts of data, we feel that the project work has met the needs for efficiency.
We managed to successfully create a tool that anonymised data inputted by the user in various formats. Our tool accepts data and anonymises it accordingly with the user’s configurations so that the data no longer contains sensitive information and could be sent through the Core Analytics System. The avoidance of transmitting sensitive data also ensure that data protection laws are followed. We also extended the Core Analytics System by adding an open-source visualiser tool which allows users to visualise the data in many different formats. This solution is particularly effective because any authorised user could access this system and the running costs will remain the same. We successfully met the requirements laid out to us by the client.
The code for the anonymiser should be easy to maintain and extend. The template pattern allows to easily add new column types. Gradle is used for dependency management, so the newest software packages are always available. JavaFX allows us to easily customise the UI. The visualiser should also be easy to maintain, because Kibana and Elastic Stack are open source projects and many people regularly contribute to these projects to extend their features, so our system will always have new updates and security fixes.
We feel that throughout the project, we have been able to plan effectively and have completed implementation phases in good time. However, should we undertake this project again, we would be eager to ensure that internal deadlines are stricter. During this project, althought internal deadlines had been set, it was often met with incomplete work. As a result, the project would have benefited with strict deadlines.
In the future, we see our project used across the healthcare industry, not only would this provide cost savings with data analytics but also with anonymisation. However, there will be dangers with these systems, especially those surrounding privacy and data protection issues. When dealing with patient data, it is very important to maintain confidentiality throughout the entire process.
Nevertheless, in the future, we see the analytics system expanding and the anonymisation tool used across the nation. With the introduction of a cluster running the analytics system and a growing number of users, there may scalability issues which can be solved by ensuring the system is supported by suitable infrastructure. This would support huge amounts of both data and users, and bring benefits to medical visualisations and research.